目录
0.前言
最近需要做一个实例分割的任务,接触到了yolact++。也是刚开始学习,只会用不知道内部啥原理,等需要的时候再去看吧。
先说点儿不相关但比较重要的:计算机视觉中有几大任务(有说四大的有说五大的,但其实大类就那么几种),图片分类、目标检测、实例分割等(还有图片定位、语义分割等,但我感觉差不太多(只是从应用的角度来看)),之前做过图片分类(用的VGG16做的迁移学习)和目标检测(yolov5),这是我第一次接触到实例分割(yolact++),还挺有意思的。给我的感觉就像在PR里面抠图。
关于计算机视觉几大任务的介绍
1.整个流程
我们先对整个流程做一说明,然后再具体说每一步怎么做。整个流程为:
(1)下载Github上的项目
(2)使用labelme打标签
(3)制作COCO格式的数据集
(4)改data/config.py文件
(5)开始训练
(6)测试
其实整个流程真的挺简单的。
2.具体过程
2.1 下载Github上的项目
GitHub上的项目地址在这里:GitHub yolact++
直接下载下来就好,不过我还是建议你下载我这里放的项目,因为这个项目已经下载好了官方之前训练好的模型文件,也对config.py文件进行了相应的修改,只需要进行简单的操作就能训练模型了。当然你直接下载GitHub上的一步步改也没问题。
链接:https://pan.baidu.com/s/1caQjPLKFiw9H6QUocTactg
提取码:syh1
资源来源于B站UP主:小鸡炖技术
资源来源-B站UP主-小鸡炖技术
下载并解压后发现里面有两个文件:cocoapi和yolact-master

这里还是建议用conda创建虚拟环境,没conda的去安装个Anaconda吧。
(1)创建虚拟环境yolact
conda create -n yolact python=3.7
conda activate yolact
(2)安装需要的依赖库
conda install pytorch torchvision cudatoolkit=10.0
pip install cython opencv-python pillow matplotlib
pip安装失败的可以换清华镜像试试:
pip install cython opencv-python pillow matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/
(3)进入cocoapi/PythonAPI文件夹并安装
cd cocoapi/PythonAPI
python setup.py build_ext install
(4)进入external/DCNv2文件夹并安装
cd external/DCNv2
python setup.py build develop
cd后面的路径根据你的来改。
按上面的步骤准备好后应该就没什么问题了,测试下环境是否弄好了:
python eval.py --trained_model=weights/yolact_plus_resnet50_54_800000.pth --score_threshold=0.15 --top_k=15 --image=test.jpg
出现下面的结果说明弄好了:

否则说明某一步有错,自己好好检查下,可以跟着B站的视频仔细检查,或者自行百度。B站视频-小鸡炖技术
labelme_76">2.2 使用labelme打标签
之前训练yolov5的时候用过labelimg来打标签,当时觉得一个矩形一个矩形画太痛苦了,直到我用了labelme,居然要用多边形把目标一个一个抠出来!啊不过你也确实没有更好的办法了。倒是没什么难度,就是体力活。labelme的界面跟labelimg长得差不多:
这是labelimg的界面:

这是labelme的界面,也就是咱们一会儿要用的标注工具:

labelme_84">2.2.1 安装labelme
安装我是参考的B站这个UP主来的,说得特别详细。他是用conda新建了虚拟环境,不过不用虚拟环境倒是也没啥问题。
B站-如何安装并使用labelme
2.2.2 如何标注
在标注前我们先看下yolact-master\data\coco文件夹下面有什么:

每个文件夹下放什么下面说:
视频里对于labelme的使用也介绍得很详细,其实就是用一个个的点把你的目标给描出来。具体操作如下:
(1)准备好你的数据集,把你的数据集分成两份,一份放在yolact-master\data\coco\train2014文件下,作为训练集,一份放在yolact-master\data\coco\val2014文件夹下,作为测试集。
(2)打开lebelme工具,对两个文件夹下的图片分别进行标注,生成的.json文件直接放在相应文件夹里就行,最后的yolact-master\data\coco\train2014文件夹下长这样:

2.3 制作COCO格式的数据集
我们需要把2.2中标注好的数据集转换成COCO格式的,这样才能训练。其实转换方法很简单:
(1)先激活之前创建好的yolact虚拟环境(如果已经激活就不用管了):
conda activate yolact
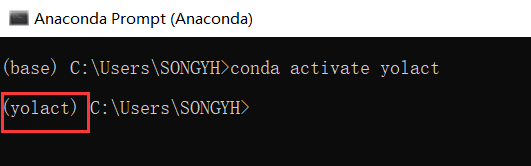
(2)cd到train2014文件夹下:
比如我的命令是:
E:
cd E:\0_postgraduate\yolact_tutorials\yolact-master\data\coco\train2014
(3)然后直接运行labelme2coco.py就行
python labelme2coco.py
这里应该会提醒你缺少相应的库,用pip安装就行,要是速度慢就像前面说的那样换成清华镜像。成功运行后会得到instances_train2014.json文件。
同样的步骤,cd到val2014文件夹下,然后运行labelme2coco.py得到instances_val2014.json文件。
(4)将得到的instances_train2014.json和instances_val2014.json文件移动到annotations文件夹下,像下面这样:

最后可以放一些要检测的图片在test2014文件夹下。
至此,COOC格式的数据集就准备好了。
2.4 改data/config.py文件
在训练前我们需要对yolact-master/data/config.py进行修改,具体只用改两处:
第一处(159行):

把class_names里面的类别改成与你的数据集对应的。这里注意,如果只有一类的话需要像我一样加个","。
第二处(820行):
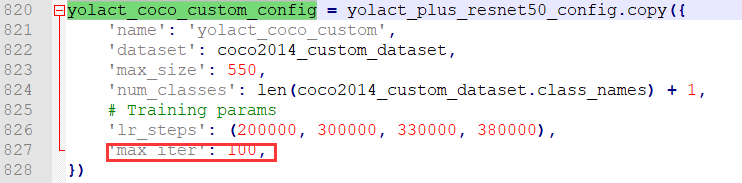
这里修改max_iter,即你的最大迭代次数。
2.5 开始训练
cd到yolact-master文件夹下,运行下面的命令
python train.py --config=yolact_coco_custom_config --resume=weights/yolact_plus_resnet50_54_800000.pth --only_last_layer --batch_size 2
这里使用的迁移学习(因为数据集较少),–resume后面跟的是基模型,这里已经下载好了不用管,–only_last_layer 意思是只训练模型的最后一层,所以速度很快,也不会占用太多内存。(我的1050,8G内存还能训练呢)。–batch_size是设定每次训练的batch,默认是8,如果报错可以改小点,我改成2就可以了。
训练可能会提前结束,等训练好之后就会在yolact-master\output文件夹下面得到你的训练模型,比如我的是这样:

至此,训练模型结束。
2.6 检测模型
最后对模型进行检测,我们找一些图片放在yolact-master\data\coco\test2014文件夹下,然后使用命令:
python eval.py --trained_model=weights/这里是你训练得到的.pth模型 --score_threshold=0.15 --top_k=15 --images=这里是你放的测试数据地址:这里是你希望输出结果的位置
比如对于我来讲,命令为:
python eval.py --trained_model=output/yolact_coco_custom_39_400.pth --score_threshold=0.15 --top_k=15 --images=data\coco\test2014:results
测试结果如下:


还不错吧,毕竟我的训练集也就20多张图片。
想检测视频的话GItHub上也有说怎么做:
GitHub官网方法
3.总结
整个过程不算特别复杂,但还是那句话,不要奢望只看一篇博客就能解决自己的所有问题。我能保证大体过程没问题,但具体遇到的细节问题肯定每个人都不一样,所以遇到细节问题还是要多百度解决。祝你成功:)